Previously we
have thought about how we can think of a system of metaheuristic synchronization as a form of computational architecture, based on the path integral interpretation:

In the classical picture of such a network,
which have local energy minima, we have a network made up of binary nodes
(activations either 0 or 1), where the probability of achieving a coupling between
the nodes would be set to 1 if and only if the connected nodes have the same
activation, i.e A1=A2, i.e. the 2 activation levels have an allowed crossing. This
has the effect of greatly limiting the nodal capacity of such systems.
To solve this problem we must relate our
quantum mechanical system to equilibrium dynamics which will allow us to create
a meta-heuristic representation of quantum diabatic behaviour which will induce
the necessary condition of avoided crossing between nodes in the
network.
Diabatic transitions can in fact be
represented as a meta-heuristic algorithm therefore one need not go through the
trouble of constructing a quantum computer to simulate annealing in the optimum
way. For example, one thing that a metaheuristic, under the lens of the path
integral interpretation of quantum mechanics, can do is a form of
self-generating noise correction.
Using quantum dynamics, we can say that the Probability of a Diabatic Transition between 2 discrete energy levels E1
and E2 is given by the Landau-Zener Formula:


Where:


Where

is the Landau-Zener Velocity for the
perturbation variable q (where q is either a quantisation, i.e. a charge, of an
electric or magnetic field, the length scale of a molecular bond, or any other
perturbation to the system), and E1 and E2 are the energies of the
two diabatic (crossing) states.
The quantity g is the off-diagonal coupling element
of the two-level system's Hamiltonian that couples the crossing states, and as
such it is half the distance between the two unperturbed eigenenergies at the
avoided crossing, when E1 = E2.
We can write the transition probability as:
The adiabatic theorem in quantum
mechanics therefore tells us, that as the difference between the energy states,Goes
to 0, then the transition probability
goes
to 1 (unity).
The adiabatic theorem in quantum mechanics therefore tells us, that as the difference between the energy states, α, Goes to 0, then the transition probability PD goes to 1 (unity).
This means that the quantised transitions between the energy states themselves are suppressed at the point of avoided crossing where 2 or more eigenvalues of the Hamiltonian cannot become equal in value.
This implies reversibility – i.e. no net work done, in a cyclic process.
In terms of thermal dynamics then we examine the transition probability in terms of the Energy Hamiltonian.
A quantum mechanical system is described by an eigenvalue problem.
Hψn = e(n)ψn
where H is a Hermitian operator on function-space, ψn is an eigenfunction,
and e(n) is the corresponding (scalar) eigenvalue.
In this case H is the Energy Hamiltonian, and the eigenvalue e(n) denotes the n-th energy level.
A quantum mechanical system is described by an eigenvalue problem.
Hψn = e(n)ψn
where H is a Hermitian operator on function-space, ψn is an eigenfunction,
and e(n) is the corresponding (scalar) eigenvalue.
In this case H is the Energy Hamiltonian, and the eigenvalue e(n) denotes the n-th energy level.
In Thermal Equilibrium Dynamics:
Since the occupation space can only be |0>
or |1> for fermions,

An imaginary time path integral approach to thermal equilibrium dynamics can be performed by the fact that our canonical density operator

Is related to the time evolution operator in the Schrödinger scheme

By the analytic continuation of time, we define:

This is known in field theory as a Wick
rotation from a Minkowskian to a Euclidean coordinate system used in field theory.
However, as we have shown, we can write the transition probability as a sum over histories in the path integral interpretation and furthermore can represent the path integral as a meta-heuristic signalling scheme in a neural network.
We can then unite the approach to achieve
meta-heuristic synchronization with the adiabatic theorem of equilibrium
dynamics which is where the longer the thermal system is allowed to transition to
reach its final state in the time evolution from x0 to xt, the more likely it
will have stayed in the ground state (or, said another way, the longer the
system is allowed to run, the less likely there is to be random excitations,
which basically translate to noise).
Therefore, in order to reduce noise or error
in such a system, all you need to do with a metaheuristic algorithm is to
simply run the algorithm in the adiabatic fashion for a longer time. i.e. if
you ran it for T = infinity, you'd be 100% accurate.
This is exactly the criterion for the
standard metaheuristic signalling algorithm, as the signalling actions move
towards the least signalling, and thus most energetically conservative, action possible.
This leads us to thinking of the metaheuristic concept of a neural
network as being applicable to the classical Boltzmann Machine Framework which can overcome the problem
of systems of binary nodes getting stuck in local energy minima by the addition
of three key features:
- Stochastic
activation function: the
state a unit is in is probabilistically related to its Energy gap. The bigger the
energy gap between its current state and the opposite state, the more
likely the unit will flip states.
- Temperature
and simulated annealing: the
probability that a node is on is computed according to a activation
function of its total weighted summed input divided by T. If T is large,
the network behaves very randomly. T is gradually reduced and at each
value of T, all the units' states are updated. Eventually, at the lowest
T, units are behaving less randomly and more like binary threshold units.
- Contrastive
Learning: A
Boltzmann machine is trained in two phases, "clamped" and
"unclamped". It can be trained either in supervised or
unsupervised mode; this type of training proceeds as follows, for each
training pattern:
- Clamped
Phase: The
input units' states are clamped to (set and not permitted to change from)
the training pattern, and the output units' states are clamped to the
target vector. All other units' states are initialized randomly, and are
then permitted to update until they reach "equilibrium" (simulated
annealing). Then learning is applied.
- Unclamped
Phase: The
input units' states are clamped to the training pattern. All other units'
states (both hidden and output) are initialized randomly, and are then
permitted to update until they reach "equilibrium". Then anti-
learning (learning with a negative sign) is applied.
The above two-phase learning rule must be
applied for each training pattern we feed into the network and for a great many
iterations through the whole training set. Eventually, the output units' states
should become identical in the clamped and unclamped phases, and so the two
learning rules exactly cancel one another. Thus, at the point when the network
is always producing the correct responses, the learning procedure naturally
converges and all weight updates approach zero.
The stochasticity enables the Boltzmann
machine to overcome the problem of getting stuck in local energy minima, while
the contrastive learning rule allows the network to be trained with hidden
features and thus overcomes the capacity limitations.
In the Boltzmann Machine framework, the state of the network is defined by an Energy Landscape.
The global energy, , in a Boltzmann machine is identical in form to that of a Hopfield energy network:


Where:
- is the connection strength between unit and unit .
- is the state, , of unit .
- is the bias of unit in the global energy function. ( is the activation threshold for the unit.)
 is the connection strength between unit
is the connection strength between unit  and unit
and unit  .
. is the state,
is the state,  , of unit
, of unit  is the bias of unit
is the bias of unit  is the activation threshold for the unit.)
is the activation threshold for the unit.)
Often the weights are represented in matrix form with a symmetric matrix , with zeros along the diagonal.
 , with zeros along the diagonal.
, with zeros along the diagonal.
The difference in the global energy that results from a single unit being 0 (off) versus 1 (on), written , assuming a symmetric matrix of weights, is given by:


This can be expressed as the difference of energies of two states:

We then substitute the energy of each state with its relative probability according to the Boltzmann Factor (the property of a Boltzmann distribution that the energy of a state is proportional to the negative log probability of that state):

where is Boltzmann's constant and is absorbed into the artificial notion of temperature .We then rearrange terms and consider that the probabilities of the unit being on and off must sum to one:

 .
.





We can now finally solve for , the probability that the -th unit is on.


where the scalar is referred to as the temperature of the system.
The above function is of course a logistic sigmoid function, with the same form as the activation function in neural networks.
Note: when T = 0 this gives a discrete step function for this probability and gives a uniform probability of 0.5.
The Boltzmann machine neural network is run by repeatedly choosing a unit and setting its state according to the above formula. After running for long enough at a certain temperature, the probability of a global state of the network will depend only upon that global state's energy, according to a Boltzmann distribution, and not on the initial state from which the process was started.
This means that log-probabilities of global states become linear in their energies. This relationship is true when the machine is "at thermal equilibrium", meaning that the probability distribution of global states has converged.
If we start running the network from a high temperature, and gradually decrease it until we reach a thermal equilibrium at a low temperature, we may converge to a distribution where the energy level fluctuates around the global minimum. This process is called simulated annealing.
It can be shown that after a certain time at fixed T, such networks reach a thermal equilibrium in which the probability of a given configuration of units is constant. Thus, while the precise state of the machine cannot be known, it is possible to reason about where it 'probably' is.
For two such configurations A and B, suppose the respective energies are Ea and Eb and the associated probabilities P(A) and P(B) it can be shown that


where K is a constant depending on the interconnections, weights and temperature. Thus the state with the lowest energy has the highest probability.
If we gradually reduce T, we have a high probability of achieving a global minimum for the system energy. At high T we locate coarse minima, which are refined as T reduces (*see note). This is the criterion for simulated annealing.
[ *Note: Another way to think about this is that when a system loses heat to its surroundings, the entropy of the system decreases and the entropy of the surroundings increases. Assuming the heat transfer occurs reversibly, then
ΔS=∫δq/T
where T is the temperature, and δq is negative for the system since the system is losing heat.
Hence the maximum change in entropy should occur at the lowest temperature. This maximum change in entropy gives us, equivalently, a perfectly uniform energy distribution, represented in terms of the logistic function being reduced to a completely convex energy basin with no bumps at all. Yet another way to picture such a state is in terms of the occupation of quantised energy levels, or rather the amount of time the machine stays at a particular energy level as thermal energy is removed. Once T=0 the length of time the machine stays in the ground state, the global minimum, will be infinite.
In reality, no ideal arrangement such as this can be reached with any real Boltzmann machine as there are always vacuum energy fluctuations that create the non-zero background temperature. Even a quantum computer working as a Boltzmann Machine at near-absolute zero would not have a truly uniform energy distribution such that you would be guaranteed to find the global minimum. ]
As in any neural network, the units in the Boltzmann machine network are divided into 'visible' units, V, and 'hidden' units, H.
The visible units are those which receive information from the 'environment', i.e. our training set is a set of binary vectors over the set V.
We hope to train the weights such that when the input units are held at the appropriate 0,1 values ( clamped) the output units display the appropriate output pattern after annealing.
This is done by performing the following cycle the necessary number of times;
The distribution over the training set is denoted .

As is discussed above, the distribution over global states converges as the Boltzmann machine reaches thermal equilibrium.
We denote this distribution, after we marginalize it over the hidden units, as .

Our goal is to approximate the "real" distribution using the which will be produced (eventually) by the machine.
To measure how similar the two distributions are, we use the Kullback–Leibler divergence, :


where the sum is over all the possible states of . is a function of the weights, since they determine the energy of a state, and the energy determines , as promised by the Boltzmann distribution. Hence, we can use a gradient descent algorithm over , so a given weight, is changed by subtracting the partial derivative of with respect to the weight.


There are two phases to Boltzmann machine training, and we switch iteratively between them. One is the "positive" phase where the visible units' states are clamped to a particular binary state vector sampled from the training set (according to ). The other is the "negative" phase where the network is allowed to run freely, i.e. no units have their state determined by external data. Surprisingly enough, the gradient with respect to a given weight, , is given by the very simple equation (proved in Ackley et al):

![\frac{\partial{G}}{\partial{w_{ij}}} = -\frac{1}{R}[p_{ij}^{+}-p_{ij}^{-}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/a0c83d95b86d28bcede06faaa1df7de1e8553c31)
where:
- is the probability of units i and j both being on when the machine is at equilibrium on the positive phase.
- is the probability of units i and j both being on when the machine is at equilibrium on the negative phase.
- denotes the learning rate
 is the probability of units i and j both being on when the machine is at equilibrium on the positive phase.
is the probability of units i and j both being on when the machine is at equilibrium on the positive phase. is the probability of units i and j both being on when the machine is at equilibrium on the negative phase.
is the probability of units i and j both being on when the machine is at equilibrium on the negative phase. denotes the learning rate
denotes the learning rate
This result follows from the fact that at thermal equilibrium the probability of any global state when the network is free-running is given by the Boltzmann distribution(hence the name "Boltzmann machine").
 of any global state
of any global state  when the network is free-running is given by the Boltzmann distribution(hence the name "Boltzmann machine").
when the network is free-running is given by the Boltzmann distribution(hence the name "Boltzmann machine").
Remarkably, this learning rule is fairly biologically plausible because the only information needed to change the weights is provided by "local" information. That is, the connection (or synapse biologically speaking) does not need information about anything other than the two neurons it connects. This is far more biologically realistic than the information needed by a connection in many other neural network training algorithms, such as backpropagation.
The training of a Boltzmann machine does not use the EM algorithm, which is heavily used in machine learning. By minimizing the KL-divergence, it is equivalent to maximizing the log-likelihood of the data. Therefore, the training procedure performs gradient ascent on the log-likelihood of the observed data. This is in contrast to the EM algorithm, where the posterior distribution of the hidden nodes must be calculated before the maximization of the expected value of the complete data likelihood during the M-step.
Training the biases is similar, but uses only single node activity:
![\frac{\partial{G}}{\partial{\theta_{i}}} = -\frac{1}{R}[p_{i}^{+}-p_{i}^{-}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/d432e59f276d5ade2f2d2a4b95071eadb57711b8)
Boltzmann learning is very powerful, but the
complexity of the algorithm increases exponentially as more neurons are added
to the network. This makes learning is impractical in general Boltzmann machines. However, learning in Boltzmann Machines can be made quite efficient in an architecture called the "Restricted Boltzmann machine" or "RBM" which does not allow intralayer connections between hidden units.
The hidden nodes in an RBM are not interconnected as they are in regular Boltzmann networks. Once trained on a particular feature set, these RBM can be combined together into larger, more diverse machines, such as polymer rings of different nodes.
The hidden nodes in an RBM are not interconnected as they are in regular Boltzmann networks. Once trained on a particular feature set, these RBM can be combined together into larger, more diverse machines, such as polymer rings of different nodes.
Because Boltzmann machine weight updates only
require looking at the expected distributions of surrounding neurons, it is a
plausible model for how actual biological neural networks learn.
Boltzmann learning is statistical in nature, and
is derived from the field of thermodynamics. It is similar to error-correction
learning and is used during supervised training. In this algorithm, the state
of each individual neuron, in addition to the system output, are taken into
account. In this respect, the Boltzmann learning rule is significantly slower
than the error-correction learning rule.
Restricted Boltzmann Machine learning is
particular interest when considering so-called Polymer Rings and the means used
to simulate them. Polymer rings are essentially compact
Gaussian chains of individual Restricted Boltzmann machines subject to strong
interactions with neighboring chains due to the presence of topological constraints.
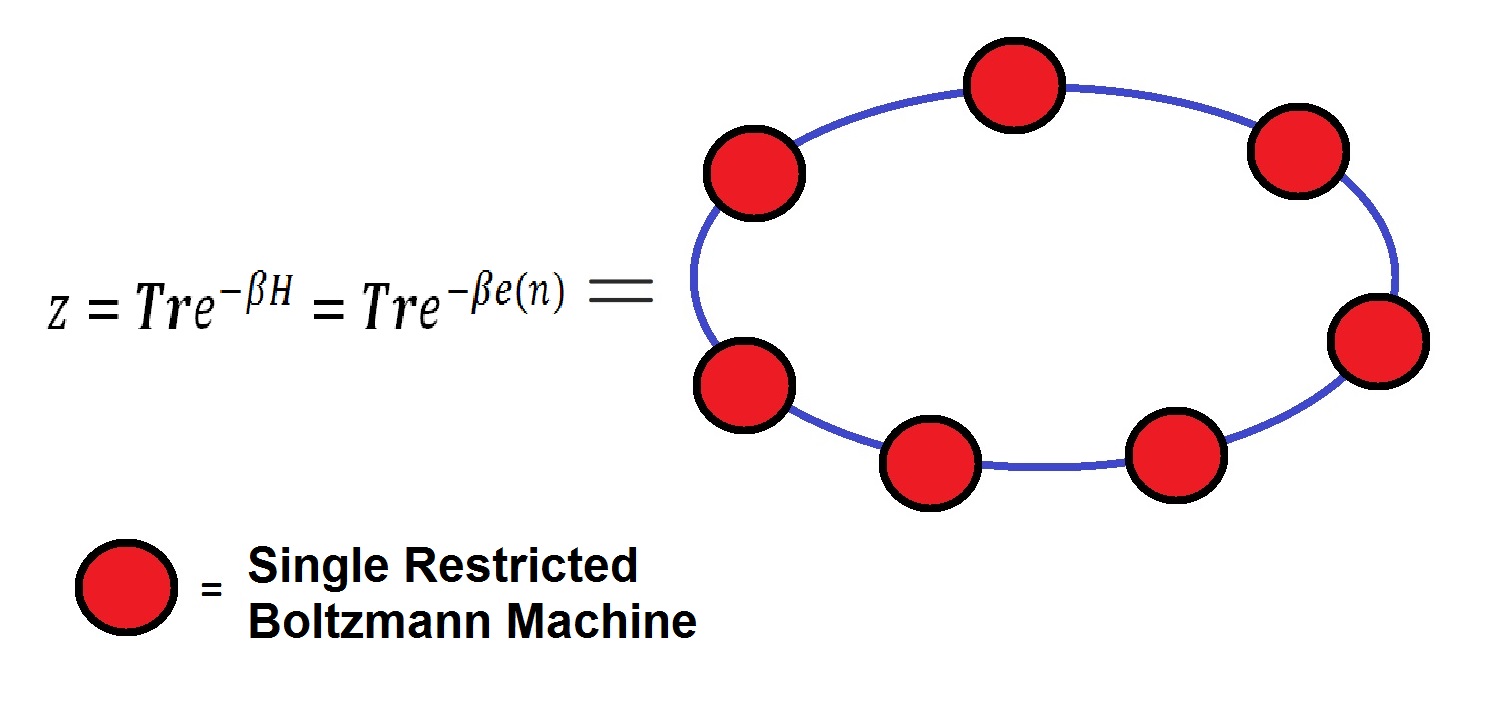
Therefore, using imposed constraints on individual single Boltzmann Machines, one can perform ring polymer simulations that use a Restricted Boltzmann Machine to model the dynamics of networks much faster than using standard unconstrained Boltzmann machines.
A constraint can be established by means of restricting communication between each individual Boltzmann machine by a search procedures, such that only the nearest neighbors to each individual Boltzmann machine is activated by its closest neighbors and ignores everything else. Such a search procedure, based on nearest neighbors, could be accomplished using a variety of already established methods.
By the path-integral interpretation of machine signalling, any system with sufficient discontinuous pas-coupling should therefore have a self-generating property of meta-heuristic behaviour.
In such a case the nodes involved with carrying out the neural activity are themselves already active in an ad-hoc synchronization procedure which organizes the nodes such that the least action principle of signalling can occur between the nodes.
In such a case, we need not even think about this in the sense of performing quantum evolution in terms of path integrals on polymer chain simulations, as doing a metaheuristic simulation should be functionally equivalent as a quantum path integral in this view.
This is the reasoning for how it is possible to use metaheuristics to solve NP-hard problems. Quantum computing of this kind, although interesting in and of itself, has very broad applications in any field involving a networked topology, which spans a huge realm of empirically observed behaviour in both organic and inorganic signalling systems.
No comments:
Post a Comment
Note: only a member of this blog may post a comment.